Beyond the Limit: Introduce Mixedbread Wholembed v3

Today we're releasing Wholembed v3, our new unified, omnimodal, multilingual late-interaction retrieval model.
Wholembed v3 sets a new state-of-the-art for search, delivering best-in-class performance across languages and modalities in both academic benchmarks and real-world industrial test cases from partners across multiple business domains.
It is now publicly available on our platform and will power all new stores on Mixedbread by default going forward. Co-designed with our custom-built retrieval infrastructure, Wholembed v3 enables Mixedbread Search to deliver state-of-the-art retrieval with high throughput, low latency, and a frictionless developer experience.
A Foundation Model for Modern RetrievalLink to section
Retrieval is at the core of most agentic applications. For AI systems to be truly powerful, they need to be grounded in relevant knowledge. And AI applications are already moving far beyond simple question answering: they are operating computers, controlling robots, and performing increasingly complex knowledge work.
Yet search remains brittle, and, for many applications, still surprisingly hard to implement well. In large part, this comes down to the models and algorithms we rely on today. Much of retrieval still relies on older paradigms, which have garnered steady incremental performance gains but have not been able to keep pace with vast capability increases in other areas of AI. Inspired by this and the modeling and algorithmic breakthroughs that have transformed language models, we built Wholembed v3 to tackle current challenges, rather than simply improve on largely solved ones.
Wholembed v3 was designed from the ground up for complex, real-world retrieval across hundreds of languages and all relevant modalities, including text, audio, and vision. With it, we set out to move beyond the limits and common failure modes of traditional semantic search.
Modern Problems Require Modern EvaluationsLink to section
Two benchmarks that we found particularly insightful to help understand the limits of semantic search in the current age are LIMIT and BrowseComp-Plus, both of which map to two opposite, but very common, real-world applications.
LIMIT is a benchmark specifically designed to stress-test the limits of semantic retrieval under situations where the documents contain a lot of fine-grained, "structured-like" information expressed as natural text. In our experience working with customers across domains, we have found this kind of document to be extremely common across many industries. Yet, they are rarely captured by common retrieval benchmarks. LIMIT has thus represented an important frontier for semantic retrieval, with older, lexical-based methods vastly outperforming even the best billion-parameter semantic retrieval models.
BrowseComp-Plus, on the other hand, aims to measure how well-suited search systems are to the agent-as-a-first-class-citizen paradigm. Rather than evaluating retrievers based on retrieval metrics, which are not always well-correlated to system usefulness, they evaluate retrievers based on their ability to let an agent reach the correct answer to 830 complex deep research queries. Many of them require dozens of sequential searches to accurately answer: miss a single nugget of information and the original question remains unanswerable.
We considered besting these two benchmarks as our North Star throughout development, while also aiming to avoid any contamination: we never evaluated any in-development model checkpoints on them until preparing for this release.
| LIMIT (Benchmark to test limits of semantic search, a lot of real-world large-scale data is similar to this benchmark) | Recall@5 | Recall@10 | Recall@100 |
|---|---|---|---|
| Model | |||
| Cohere Embed 4 | 1.8 | 2.55 | 5.7 |
| OpenAI Text Embedding 3 Large | 1.75 | 2.4 | 4.95 |
| Voyage 4 Large | 1.85 | 2.9 | 8.95 |
| Gemini Embedding 2 (03/26) | 1.85 | 2.25 | 6.9 |
| BM25 | 85.7 | 90.4 | 93.6 |
| Mixedbread Wholembed V3 | 92.45 | 94.4 | 98.0 |
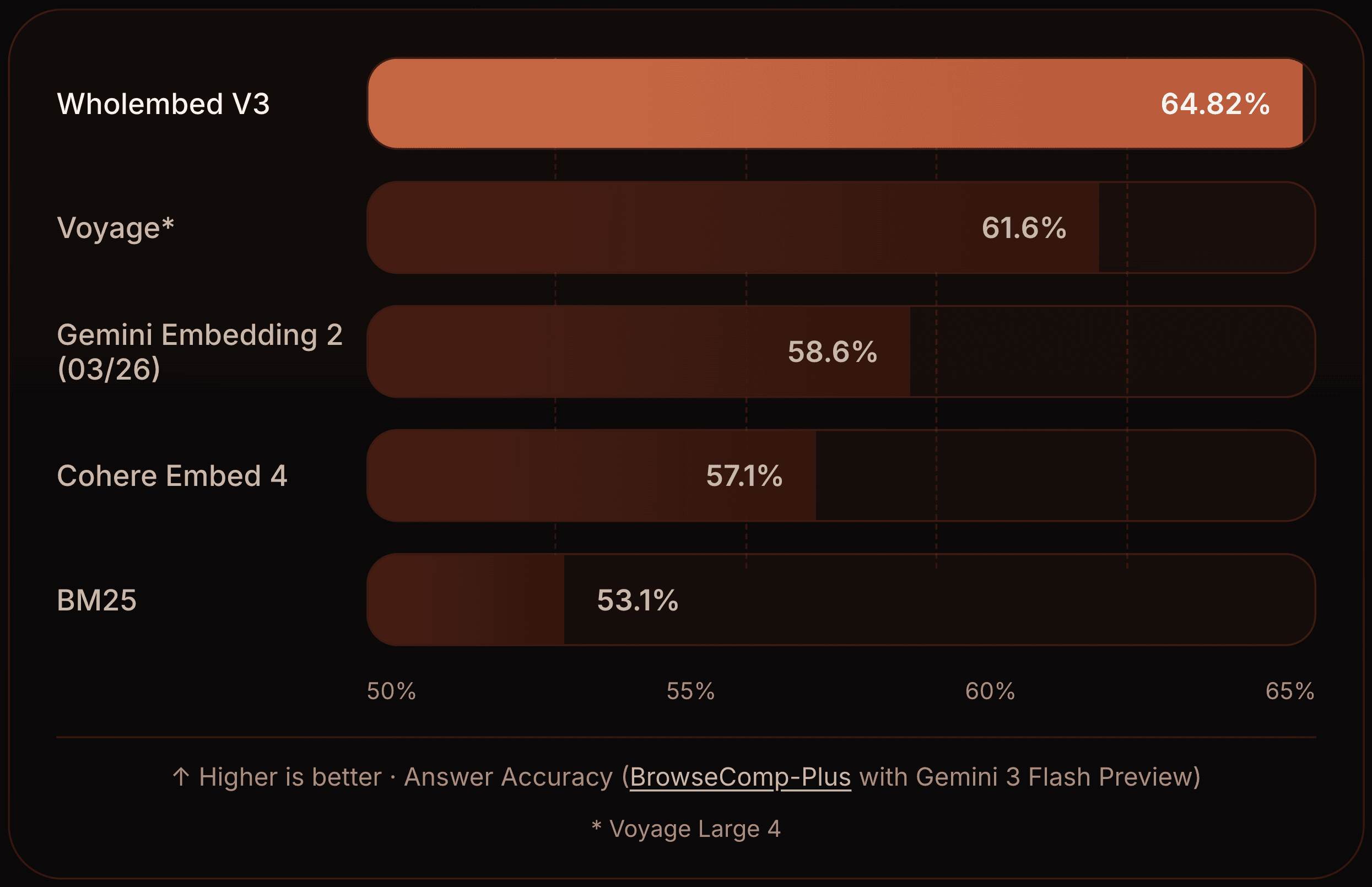
On LIMIT, Wholembed v3 pushes semantic retrieval far beyond what was previously thought possible for semantic search. It not only outperformed previous semantic methods by a margin, but also became the first model to outperform lexical-based retrieval. On BrowseComp-Plus, we observe how important the choice of retriever, such as Mixedbread Search, is for deep research agents: without a good retrieval system, hundreds more questions are answered incorrectly.
We believe this strong performance on difficult, real-world domains stems from design choices that align well with what agents need: precise retrieval, strong discrimination between similar candidates, and robustness to noisy, heterogeneous data.
Evaluating Retrieval In A Multi-Modal Multi-Lingual WorldLink to section
Wholembed v3 is not solely built around serving agents and their novel needs, but to improve retrieval for the real world: a world where information does not live in neatly pre-packaged paragraphs with clear relevance boundaries. In practice, that means a single retrieval system that can index and search text, images, audio, and video.
We strongly believe that to be useful, search needs to be able to find information where it lives: in good quality text, yes, but also in artifacts-ridden OCRised documents, scanned PDFs and screenshots with confusing names, or even in instructional videos.
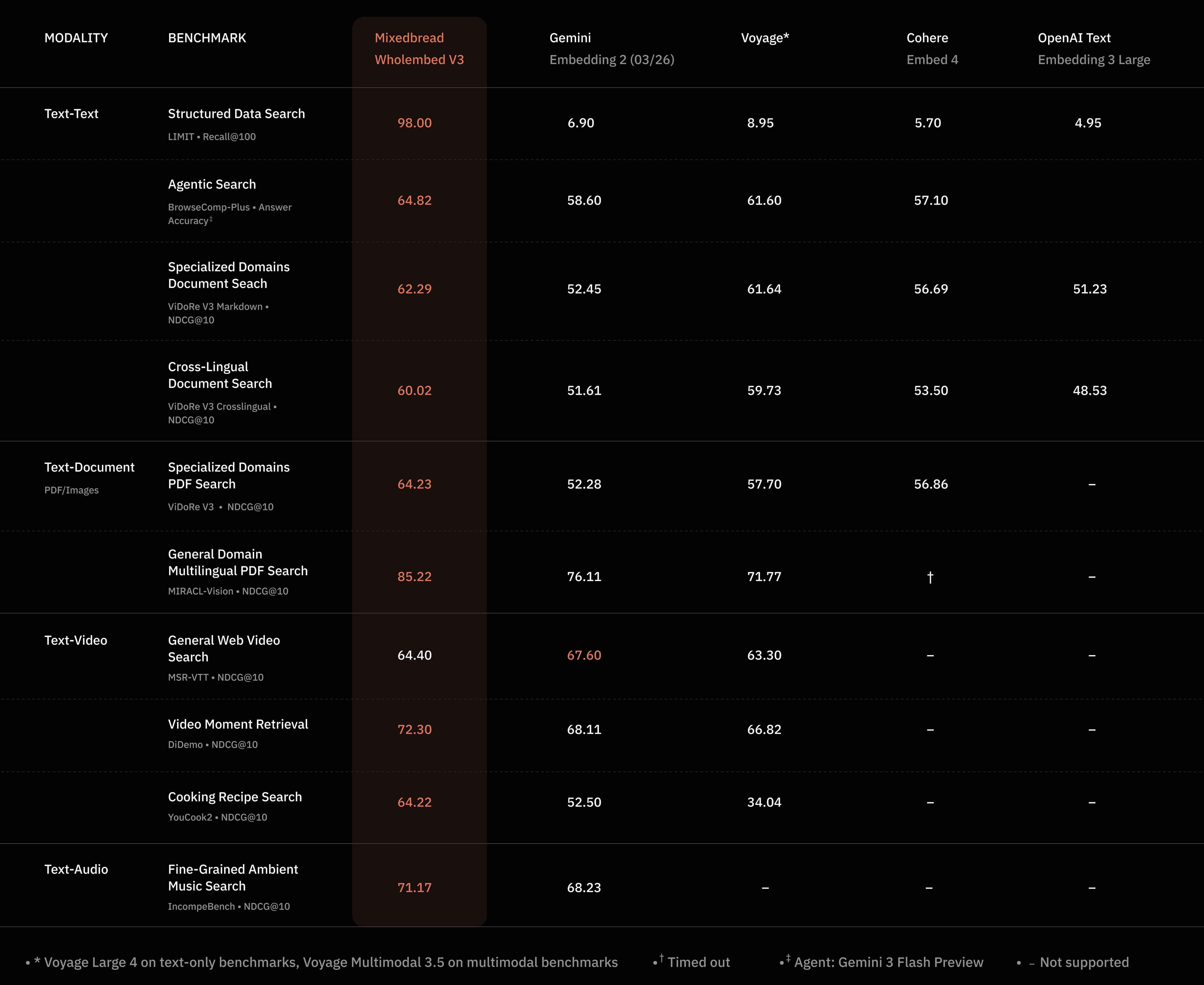
Wholembed v3 was designed with the real world in mind. Integrated with Mixedbread Search, it provides you with a seamless experience, ensuring that your service can retrieve exactly the information it needs without requiring you to think about how every single data processing detail will affect the quality of your application.
In our testing, we found that Wholembed v3 outperforms existing methods in almost all situations, no matter the document type, the kind of information you need to find or the language it’s in.
As part of our pre-release phase, we have heard from our partners that this held true across a variety of domains, with Wholembed v3 preview-powered Mixedbread Search replacing convoluted pipelines encompassing many brittle parts.
We are now very excited to finally release Wholembed v3 as our default and only model, and are looking forward to new kinds of applications it will enable. Search doesn’t need to be complicated, it just needs to be good.
Try it NowLink to section
Wholembed v3 is now available to all Mixedbread Search users. All new stores use v3 by default, with built-in support for audio and video.
New users get 2M free tokens to get started. Startups can also explore our accelerator programs with Vercel and TinyFish.
Create a store in the platform or get started directly with the API in just a few lines:
from mixedbread import Mixedbread
from pathlib import Path
client = Mixedbread()
client.stores.create(name="example")
client.stores.files.upload(
store_identifier="example",
file=Path("example.mp4")
)
client.stores.search(
store_identifiers=["example"],
query="how we bake search for the future?"
)We are building Mixedbread to close the gap between the search that is possible today and what users and agents of tomorrow will demand. If that sounds like a problem you want to work on, we are hiring.