Closing the Oracle Gap for Your Agents

In retrieval for agentic workflows, the most important number is not the raw score, but the gap to oracle.
Oracle retrieval is the ceiling: the score you get when the system has access to the correct evidence for every question, without retrieval misses. The smaller the gap, the less retrieval is holding the rest of your stack back.
Our goal with Mixedbread Search is that you should not have to think about that gap at all. Building agentic systems is already complex enough without also having to debug retrieval quality. Search should be one less thing your team has to worry about.
Across three agentic benchmarks, Mixedbread Search v3 consistently narrows that gap: on broad general-domain tasks like BrowseComp-Plus, on newer multimodal benchmarks like MADQA, and on enterprise knowledge-work benchmarks like OfficeQA-Pro. We chose these benchmarks because they stress the workflows our customers actually care about.
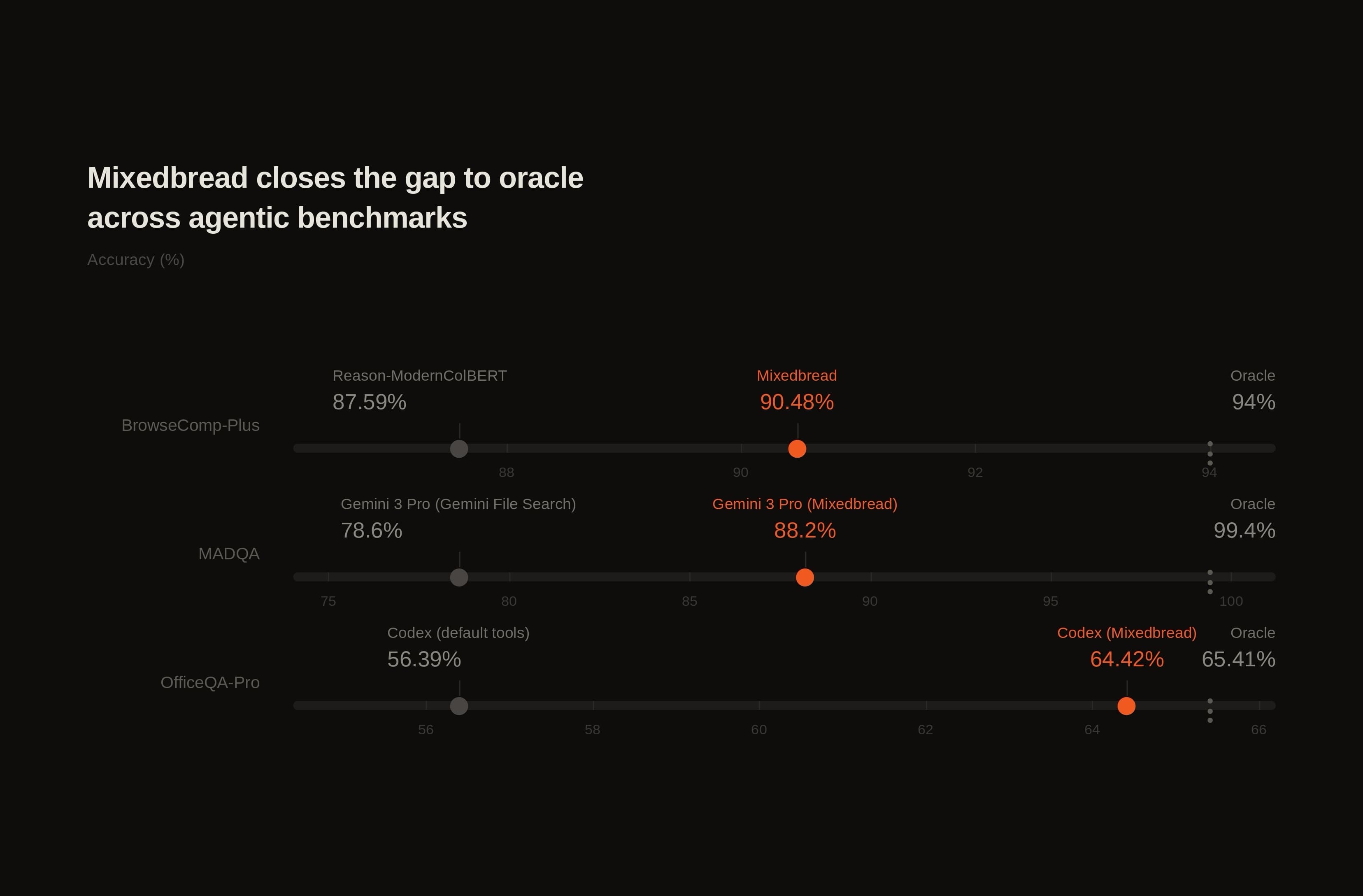
BrowseComp-PlusLink to section
BrowseComp-Plus measures deep-research agents on multi-hop questions over a corpus of roughly 100,000 web documents. It is designed specifically to separate retrieval quality from model capability.
| Retriever | Scaffold | Accuracy | Gap to Oracle (93.5%)1 |
|---|---|---|---|
| Mixedbread Search | get_document | 90.48% | 3.02 |
| Reason-ModernColBERT | get_document | 87.59% | 5.9 |
| Mixedbread Search | standard | 80.00 | 13.5 |
| Reason-ModernColBERT | standard | 79.52 | 13.98 |
| Qwen3-Embed-8B | standard | 71.69% | 21.81 |
Mixedbread Search v3 ranks #1 on the leaderboard in both settings: with the default standardized benchmarking scaffold, and with the stronger agentic scaffold where the model can read the full document behind each retrieved snippet.
Notably, the gap between Mixedbread Search and other retrieval approaches widens under the better harness. That suggests retrieval is less often the limiting factor, and that more of the remaining headroom lies in the overall agent setup. In practice, that means teams can spend less time debugging retrieval and more time improving the rest of their system.
MADQALink to section
MADQA, released just last week, tests whether agents can navigate more than 18,000 pages from 800 heterogeneous PDFs to answer 500 human-authored questions. The benchmark is inherently multimodal: models are given screenshots of PDF pages, and the dataset is designed to reflect complex in-domain knowledge across areas like financial reports and legal documents.
It can be run in two settings. In one-turn mode, the model gets a single search call before it must answer. In agentic mode, the model is given up to ten turns, with metrics that explicitly measure the tradeoff between answer quality and effort, a proxy for both token cost and system speed.
| Model | Retriever | Accuracy | Gap to Oracle (99.4%) | Page F1 |
|---|---|---|---|---|
| Human w/ Oracle Retriever | Oracle | 99.4% | 0.0 | - |
| Button, an agentic document-QA system built on Gemini 3.1 Pro (Agentic) | Hybrid w/ Mixedbread | 91.7% | 7.7 | 86.9 |
| Gemini 3 Pro (One-shot RAG) | Mixedbread | 88.2% | 11.2 | 82.2 |
| Human w/ BM25 | BM25 | 82.2% | 17.2 | 79.3 |
| Claude Sonnet 4.5 (Agentic) | BM25 | 80.6% | 18.8 | 79.1 |
| Gemini 3 Pro (Preview) with File Search | Google Files Search | 78.6 | 20.8 | 70.1 |
On the current MADQA leaderboard, Mixedbread-powered systems occupy the top spots in each category, with only a human using oracle documents outperforming them. In the single-search setting, Gemini 3 Pro with Mixedbread outperforms human experts who are allowed up to 10 BM25 searches.
Gemini 3 Pro also gains nearly 10 points of accuracy with Mixedbread compared to Google’s File Search API. Notably, the top-performing system, Button, is not ours: Distyl AI paired Mixedbread Search with its own harness and reached state-of-the-art results without further tuning.
Taken together, these results suggest that Mixedbread Search is effective at surfacing the evidence agentic workflows need, including on heterogeneous, multimodal corpora.
OfficeQA-ProLink to section
Finally, OfficeQA-Pro is a specialized enterprise knowledge-work benchmark designed by Databricks. It contains 89,000 pages of complex financial documents, including U.S. Treasury Bulletins, dense tables, and scanned PDFs, along with questions that require multi-document reasoning to answer satisfactorily.
We wanted to measure the effect of retrieval quality inside a widely used tool: OpenAI's Codex. So we ran the benchmark in the same Codex-based setup while varying only the retrieval tooling: a corpus baseline, where the raw corpus is stored on disk as OCR plus PDF images and Codex uses its usual tools; an oracle setting, where the model is given all correct documents; and Mixedbread Search-based retrieval.
This setup does not isolate retrieval as cleanly as the other benchmarks, which were designed specifically for that purpose. Still, we think it is informative because OfficeQA documents are unusually difficult, and because many teams rely on agents’ native “no-RAG” context tools in similar settings.
| Method | Correctness | Gap to Oracle | Latency (min) | Tool Calls |
|---|---|---|---|---|
| Codex (Oracle, thinking high) | 65.41 | - | 2.2* | 20.7* |
| Codex (Mixedbread, thinking high) | 64.42 | 0.99 | 2.36 | 17.35 |
| Codex (Corpus, thinking high) | 56.39 | 9.02 | 3.6 | 34.5 |
| GPT 5.4 Agent + Semantic Search ** | 51.90 | 13.51 | 8.93 | 86.4 |
With all other settings held equal, Mixedbread comes close to the oracle setting while materially reducing latency and tool use. Compared with Codex’s built-in retrieval over the corpus, Mixedbread recovers 89% of the gap between the corpus baseline and oracle (8.03 of 9.02 points) while cutting latency by 34% and reducing tool calls by roughly half.
Within the same harness, Mixedbread Search moves the agent substantially closer to oracle with less search effort.
*: performance reported from paper
**: using Databricks agent (from paper)
More Limits to OvercomeLink to section
Even with these results, knowledge work is far from solved. Hard cases remain: ambiguous queries, genuinely missing evidence, messy enterprise corpora, and tasks where the core difficulty is not finding documents but reasoning correctly over them once found.
Closing the oracle gap does not eliminate system failures, and it does not fully eliminate retrieval failures either. But as the gap shrinks, the source of failure shifts. When retrieval is less often the bottleneck, more of the remaining headroom moves to reasoning, prompting, and domain-specific system design, which is where teams are often best served spending their effort.
One API
To make retrieval one less thing teams have to manage, we built Mixedbread Search behind a simple API:
from mixedbread import Mixedbread
from pathlib import Path
client = Mixedbread()
# Index documents (any modality)
client.stores.files.upload(
store_identifier="my-store",
file=Path("doc.pdf")
)
# Search
results = client.stores.search(
store_identifiers=["my-store"],
query="quarterly revenue growth",
)No chunking decisions, embedding model choices, image preprocessing, vector database configuration, or reranker threshold tuning.
We handle multimodal ingestion, late-interaction encoding, indexing, and retrieval. You upload documents and start searching. To get started just sign up.
We are building Mixedbread to close the gap between the search that is possible today and what users and agents of tomorrow will demand. If that sounds like a problem you want to work on, we are hiring.
FootnotesLink to section
-
As reported in the BrowseComp-Plus paper. ↩