Agentic Search
A single search returns the chunks closest to one query. That works for lookups, but breaks down on questions that need multiple sources, span several time periods, or hide their best phrasing from the user. Agentic Search wraps the search endpoint in an LLM-driven loop: the agent runs parallel sub-queries, analyzes metadata facets, inspects retrieved results, and decides whether to search again before submitting a final ranked chunk list.
The response shape is identical to a normal search (a ranked list of scored chunks), so Agentic Search is a drop-in upgrade for quality-sensitive queries.
When to use itLink to section
Reach for Agentic Search when one search is not enough. Typical signals:
- The question fans out across multiple entities, years, or sources (e.g. "Compare revenue, headcount, and churn across 2020 to 2025").
- The user phrasing is conversational and underspecified, but the underlying answer needs precise terminology.
- A single top-k list keeps missing relevant chunks and/or includes irrelevant chunks because the right query isn't obvious upfront.
It is slower than a single search because of the extra LLM calls and retrievals, so use plain Search for narrow lookups and reach for Agentic Search when quality matters more than latency.
Basic UsageLink to section
Enable agentic search by setting search_options.agentic to true:
from mixedbread import Mixedbread
mxbai = Mixedbread(api_key="YOUR_API_KEY")
results = mxbai.stores.search(
query="What are the yearly numbers for 2020, 2021, 2022, 2023, 2024, 2025?",
store_identifiers=["yearly-reports"],
search_options={"agentic": True},
)
print(results)The output uses the same shape as the normal search response. When agentic is
enabled, rewrite_query and rerank are ignored, since the agent handles query
decomposition and ranking itself.
How it WorksLink to section
Each agentic search runs as a bounded loop:
- Initial search and metadata. The original query is run as-is while compact metadata facets are fetched for the selected stores. This guarantees the exact phrasing is always represented in the candidate pool, even if the agent later goes off in a different direction.
- Plan and retrieve. The agent inspects results, then either submits a
ranking or calls a retrieval tool:
search_batchfor up toqueries_per_roundsemantic sub-queries in parallel,wide_searchfor a broad high-recall query, orfilter_chunksfor single-store metadata filtering and sorting. - Iterate. Step 2 repeats until the agent has enough context or hits
max_rounds. New chunks are merged into a deduplicated pool. - Submit ranking. The agent calls
submit_rankingwith the chunks it considers most relevant. Withstrict_top_k=true, the submitted ranking is constrained to exactlytop_kchunks.
If the agent stops without submitting a ranking, the service forces one final ranking call so you always get a result back.
ConfigurationLink to section
Pass an object instead of true to tune the loop:
from mixedbread import Mixedbread
mxbai = Mixedbread(api_key="YOUR_API_KEY")
results = mxbai.stores.search(
query="What are the yearly numbers for 2020, 2021, 2022, 2023, 2024, 2025?",
store_identifiers=["yearly-reports"],
search_options={
"agentic": {
"max_rounds": 3,
"queries_per_round": 3,
"instructions": (
"Search for revenue, profitability, and headcount trends before ranking the results."
),
}
},
)
print(results)ParametersLink to section
All fields under search_options.agentic are optional.
| Parameter | Type | Default | Description |
|---|---|---|---|
max_rounds | integer | 3 | Maximum number of search rounds the agent may run (1 to 10), including the initial original-query search. Higher values give the agent more chances to refine. 1 disables follow-up searches and behaves like a normal search with LLM-driven ranking. |
queries_per_round | integer | 4 | Maximum number of sub-queries in each search_batch call (1 to 10). Sub-queries in a batch run in parallel, so this controls how wide the agent fans out during semantic search. Use max_rounds for depth and queries_per_round for breadth. |
instructions | string | null | Free-form guidance appended to the agent's system prompt (up to 2,000 characters). Use it to bias the agent toward specific entities, metrics, source types, or ranking criteria. Followed only when not in conflict with the built-in search rules. |
strict_top_k | boolean | false | When true, submit_ranking is constrained to exactly top_k chunks and the resolved ranking is capped at top_k. When false, the agent can return all the chunks it considers relevant. |
media_content | string | "auto" | Controls when image chunks discovered during the loop are passed back into the agent as image content. "auto" sends images only when no OCR text or summary is available, "always" sends image content when available for higher visual reasoning, and "never" forces text-only reasoning, which is the fastest configuration. |
Example instructionsLink to section
"Prefer primary sources over summaries when both are available.""Prioritize the most recent fiscal year, then compare year-over-year.""Treat tables and figures as authoritative; treat marketing copy as weak signal."
Combining with other featuresLink to section
The fields outside search_options.agentic still affect the agentic run:
top_k: target result size, and the exact size required whenstrict_top_k=true.filters: applied to local store retrievals, not just the original.file_ids: local store retrievals are constrained to these files.store_identifiers: semantic and wide retrievals search across all listed stores. Includemixedbread/webto let the agent pull in web search results alongside your own stores.search_options.score_threshold: applied as a final filter after ranking; can return fewer thantop_kchunks even withstrict_top_k=true.
search_options.rewrite_query and search_options.rerank are ignored when
agentic is enabled, since the agent owns query decomposition and ranking.
ObservabilityLink to section
Every agentic search emits a structured trace. The dashboard renders it as a waterfall view of LLM generations, metadata inspection, retrieval tool calls, and sub-queries, with timing and round numbers, so you can see exactly what the agent did and where time was spent:
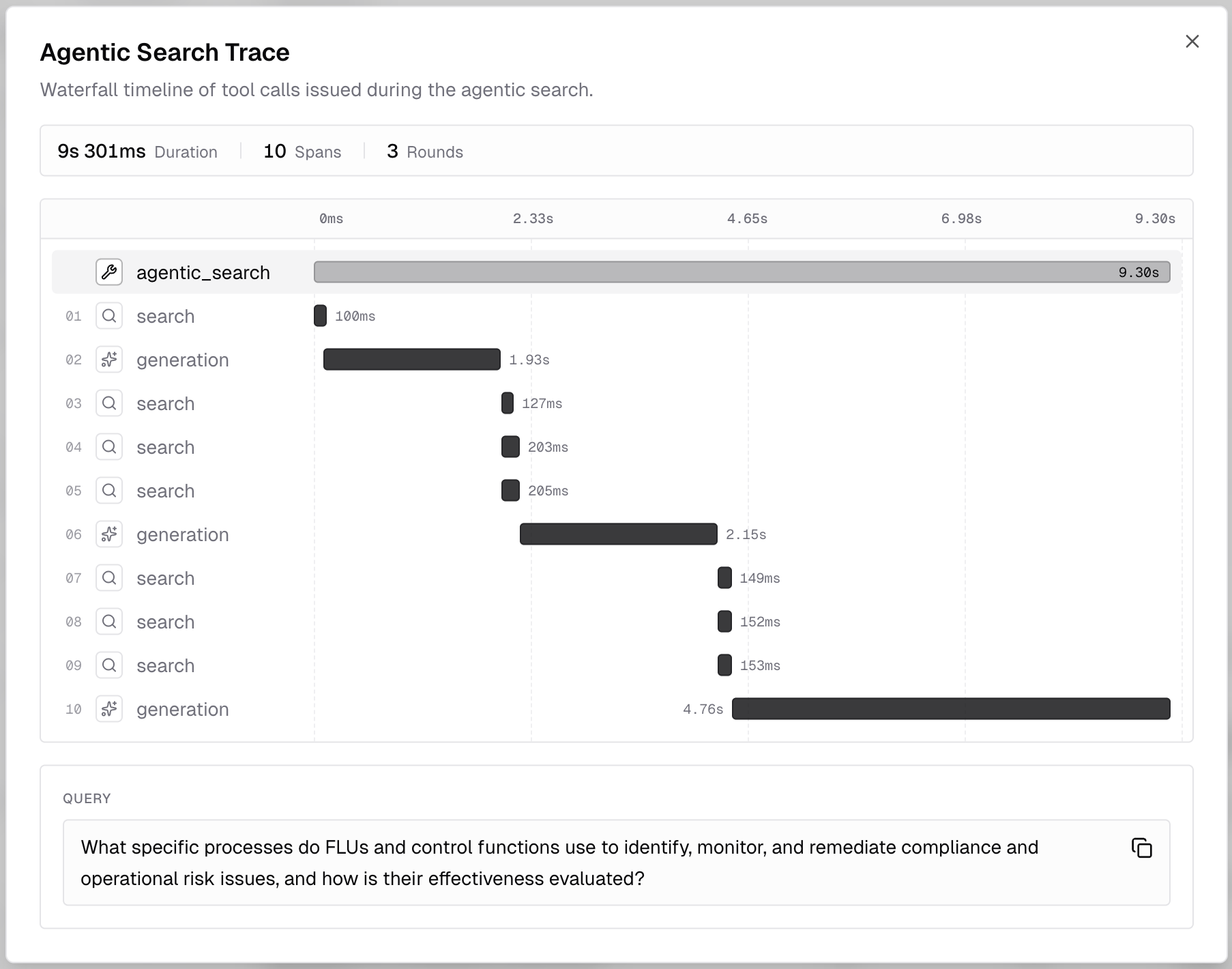
The same data is available programmatically by listing store events with
event_type=agentic_search. Each event captures the original query,
instructions, rounds executed, token usage, and the ordered list of tool calls
the agent issued (with arguments, result, duration, and any error).
Tool call fields follow the
OpenTelemetry GenAI semantic conventions,
so traces interoperate with standard observability tooling.
For the full response schema, see List Store Events. Use these events to debug unexpected results ("why didn't the agent find X?") or build dashboards on top of the agent's behavior.
TipsLink to section
- Start with the defaults.
max_rounds=3,queries_per_round=4,media_content="auto", and no instructions is a strong baseline for most workloads. - Use
instructionsto encode domain knowledge the agent can't infer from the query (e.g. preferred source types, entity disambiguation rules). - Keep
strict_top_k=falsewhen you need high precision, as the agent will not include irrelevant chunks in its output - Combine with
mixedbread/webfor hybrid runs that mix internal stores with the open web in a single ranked list. - Inspect the trace before tuning. If the agent always converges in two
rounds, lowering
max_roundssaves time. If it always burns the budget, consider a higherqueries_per_round.